本文最后更新于:2023年9月20日 凌晨
统计字符长度踩的坑
import (
"fmt"
"testing"
"unicode/utf8"
)
func TestUTF8Length(t *testing.T) {
{
s := "hello"
t.Logf("len(%s) = %d", s, len(s))
}
{
s := "你好"
t.Logf("len(%s) = %d", s, len(s))
}
}
func TestUnicodeLength(t *testing.T) {
{
s := "hello"
t.Logf("unicodeLen(%s) = %d", s, utf8.RuneCountInString(s))
}
{
s := "你好"
t.Logf("unicodeLen(%s) = %d", s, utf8.RuneCountInString(s))
}
{
s := "😄"
t.Logf("unicodeLen(%s) = %d", s, utf8.RuneCountInString(s))
}
}
func TestUnicode(t *testing.T) {
{
s := "hello z"
t.Logf("print %s", s)
RangePrint(s)
}
fmt.Println()
{
s := "你好"
t.Logf("print %s", s)
RangePrint(s)
}
fmt.Println()
{
s := "😄"
t.Logf("print %s", s)
RangePrint(s)
}
}
func TestUtf8Bytes(t *testing.T) {
{
s := "😄"
for _, b := range []byte(s) {
fmt.Printf("%#02x ", b)
}
}
}
func RangePrint(s string) {
for _, char := range s {
fmt.Printf("%U ", char)
}
}UNICODE
UNICODE 万国码 是ISO统一规范的一种字符集,给每个字符一个去标识。一个字符的Unicode编号(又称为码点)是一个 唯一数字 ,通常用十六进制表示,取值范围是0到10FFFF(转换成十进制就是0到1114111)。
UTF
Unicode是数与字符的对应关系,它是一种概念,所以它只对人类有意义。计算机不能处理和存储概念,只能处理和存储数据。所以我们必须想个办法,把Unicode的概念转换成计算机可以处理的具体数据,而这是“UTF”(Unicode Transformation Format,Unicode转换格式,Unicode转写方式)。
现今大多数计算机体系结构都使用8个二进制位做为一个字节,“UTF”的设计目的,是把Unicode规范为字符分配的编号转换为计算机可以直接存储和处理的“八位字节序列”。
UTF-8
https://en.wikipedia.org/wiki/UTF-8
1个unicode字符至少8bit位
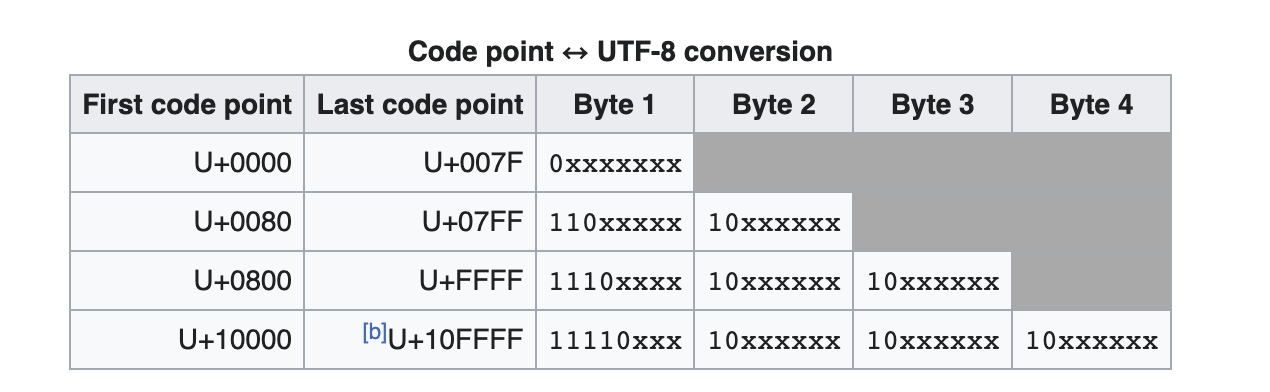
如果第一个字节是0xxxxxxx,表示该字符只有1字节。
如果第一个字节是110xxxxx,表示该字符有2字节。
如果第一个字节是1110xxxx,表示该字符有3字节。
如果第一个字节是11110xxx,表示该字符有4字节。
10xxxxxx表示尾随字节。
实际上5字节和6字节的编码不会出现,因为Unicode最大码点只到U+10FFFF,用4字节就够了。
把“虎”字及其emoji转换为UTF-8编码。
虎:
码点为 U+864E
转换为二进制,1000011001001110
从末尾开始按6位分组,1000 011001 001110
需要3字节,开头插入1110,中间插入两个10,得到 11101000 10011001 10001110
转换为十六进制,得到 E8 99 8E
虎的emoji:
码点为 U+1F405
转换为二进制,11111010000000101
从末尾开始按6位分组,得到 11111 010000 000101
第一部分为5位,开头插入1110的话就9位了,一个字节放不下,所以前面得补一个字节,用4字节表示。字节中间和末尾空隙填充0,然后每个尾随字节前面都补10,也就是 11110000 10011111 10010000 10000101
转换成十六进制,得到 F0 9F 90 85
https://tool.oschina.net/hexconvert/
解码器读取到E8就能知道第一个字符3字节。然后跳过2字节读取到F0就能知道第二个字符4字节,所以不会有边界问题。
// Numbers fundamental to the encoding.
const (
RuneError = '\uFFFD' // 当出现无法解码的字节序列或无效的Unicode字符时,Go语言会使用该替换字符来表示错误或无效的部分。
RuneSelf = 0x80 // 由utf-8定义可知,小于该值的即表示该字符本身
MaxRune = '\U0010FFFF' // Maximum valid Unicode code point.
UTFMax = 4 // 最大的utf-8编码unicode1字节数
...
xx = 0xF1 // invalid: size 1
as = 0xF0 // ASCII: size 1
s1 = 0x02 // accept 0, size 2
s2 = 0x13 // accept 1, size 3
s3 = 0x03 // accept 0, size 3
s4 = 0x23 // accept 2, size 3
s5 = 0x34 // accept 3, size 4
s6 = 0x04 // accept 0, size 4
s7 = 0x44 // accept 4, size 4
)
type acceptRange struct {
lo uint8 // lowest value for second byte.
hi uint8 // highest value for second byte.
}
var acceptRanges = [16]acceptRange{
0: {locb, hicb}, // 0x80, 0b10111111
1: {0xA0, hicb}, // 0b10100000, 0b10111111
2: {locb, 0x9F}, // 0x80, 0b10011111
3: {0x90, hicb}, // 0b10010000, 0b10111111 (标记位的范围)
4: {locb, 0x8F}, // 0x80, 10001111
}
// first is information about the first byte in a UTF-8 sequence.
var first = [256]uint8{
// 1 2 3 4 5 6 7 8 9 A B C D E F
as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x00-0x0F
as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x10-0x1F
as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x20-0x2F
as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x30-0x3F
as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x40-0x4F
as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x50-0x5F
as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x60-0x6F
as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, as, // 0x70-0x7F
// 1 2 3 4 5 6 7 8 9 A B C D E F
xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0x80-0x8F
xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0x90-0x9F
xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0xA0-0xAF
xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0xB0-0xBF
xx, xx, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, // 0xC0-0xCF
s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, s1, // 0xD0-0xDF
s2, s3, s3, s3, s3, s3, s3, s3, s3, s3, s3, s3, s3, s4, s3, s3, // 0xE0-0xEF
s5, s6, s6, s6, s7, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, xx, // 0xF0-0xFF
}
...
func RuneCountInString(s string) (n int) {
ns := len(s)
for i := 0; i < ns; n++ {
c := s[i]
if c < RuneSelf { // 小于0x80的都表示单个字符,直接继续循环计数n +1
// ASCII fast path
i++
continue
}
// first is information about the first byte in a UTF-8 sequence.
// 第一个字节(无符号256)在utf-8的位置,是16进制的xx-s7变量
x := first[c]
if x == xx {
i++ // invalid.
continue
}
size := int(x & 7) // 与 111 进行与运算 取得末7位的size值
if i+size > ns {
i++ // Short or invalid.
continue
}
accept := acceptRanges[x>>4] // 右移4位 取得accept的值
if c := s[i+1]; c < accept.lo || accept.hi < c { // 标记位范围
size = 1
} else if size == 2 {
} else if c := s[i+2]; c < locb || hicb < c {
size = 1
} else if size == 3 {
} else if c := s[i+3]; c < locb || hicb < c {
size = 1
}
i += size
}
return n
}本博客所有文章除特别声明外,均采用 CC BY-SA 3.0协议 。转载请注明出处!